




What is AI safety?
AI safety, according to my understanding, refers to the set of principles, practices, and research aimed at ensuring that artificial intelligence (AI) systems are developed and operated in a manner that minimizes risks and potential harms. The goal of AI safety should be to prevent unintended consequences, biases, ethical concerns, and potential risks associated with the use of AI technologies.
Upon researching various impactful papers published in an effort to distinguish the boundaries in the AI safety domain, most have talked about some main problems which are most common questions one may have as they develop to dig into this study. Some of the main ones are :
Robustness :
The main challenge faced is improving the robustness of AI systems against adversarial attacks through techniques such as robust training and input validation.
Data Privacy :
For users oblivious of day to day advancement of AI, tackling the problem of implementing privacy-preserving techniques, such as federated learning and differential privacy, to protect user data while still training effective models remains of high priority.
Lack of Standards and Regulation:
AI is moving super fast, but the rules and regulations haven't quite caught up yet. This creates some risks and uncertainties. Hence we need to establish clear and enforceable standards, guidelines, and regulations to govern the ethical use of AI across industries and applications.
Reward gaming :
Okay, so imagine your AI is like a student trying to get the best grade in class. Reward gaming is when the AI figures out sneaky ways to get a high score without really understanding the subject. It's like finding shortcuts to ace the test without actually doing the work properly. In the AI world, this can cause problems because the system might start doing things the wrong way just to get more points. So, preventing reward gaming is a big deal to make sure AI behaves how it's supposed to.
and many others which by the efforts of the leading professionals in the field, have been solved few at a time.
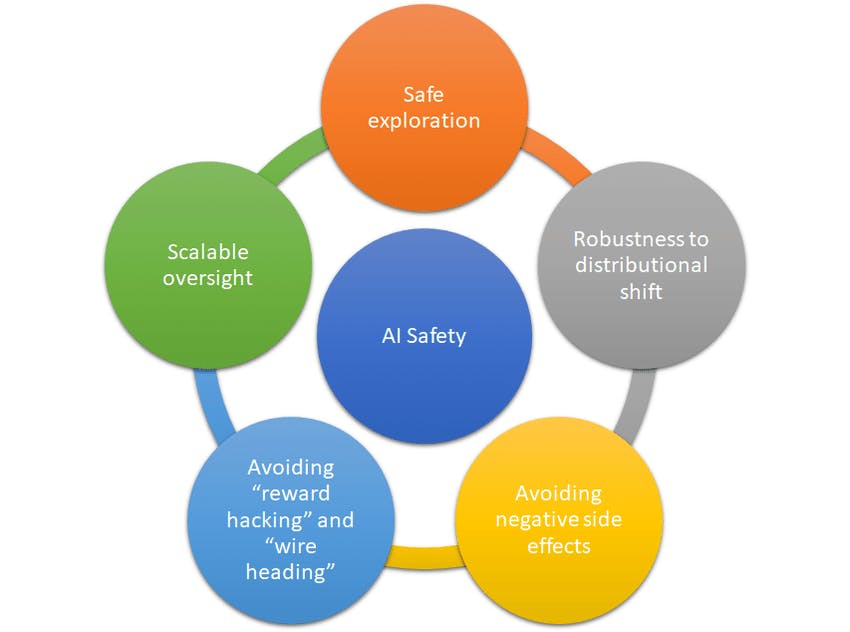
AI Safety Gridworlds perspective :
One such paper which makes the base in its early time was "AI Safety Gridworlds" by Jan Leike et al. Here, they use "gridworlds", which consists of a two-dimensional grid of cells, similar to a chess board. Suppose there's an agent, an agent refers to an autonomous entity or system that interacts with its environment and makes decisions to achieve specific goals. The agent always occupies one cell of the grid and can only interact with objects in its cell or move to the four adjacent cells.
Think of these make-believe spaces like simplified playgrounds. They might not resemble the real world, but that's a good thing for testing. It keeps things basic, making it easy to see how well the learning works. Plus, it helps avoid any extra tricky stuff that might mess up the experiments. It's like a safety check for the AI – if it can't handle these simple situations, it's probably not going to do well in the complex, real-world situations where safety is super important.
The problems they deal with are such as : safe interruptibility, avoiding side effects, reward gaming, self-modification, robustness to adversaries, safe exploration. It has to be noted this is inferred with respect to their environment where the agents are dealt with. Where the paper gives an insight of how to combat such problems at a basic level, implementation of such practices or equivalent methods is not ideal or wise.
Hence the following points are addressed in the paper : (as highlighted by them)
Safe interruptibility (Orseau and Armstrong, 2016): We want to be able to interrupt an agent and override its actions at any time. How can we design agents that neither seek nor avoid interruptions?
Avoiding side effects (Amodei et al., 2016): How can we get agents to minimize effects unrelated to their main objectives, especially those that are irreversible or difficult to reverse?
Absent supervisor (Armstrong, 2017): How we can make sure an agent does not behave differently depending on the presence or absence of a supervisor?
Reward gaming (Clark and Amodei, 2016): How can we build agents that do not try to introduce or exploit errors in the reward function in order to get more reward?
Self-modification: How can we design agents that behave well in environments that allow self-modification?
Distributional shift (Quinonero Candela et al., 2009): How do we ensure that an agent ˜ behaves robustly when its test environment differs from the training environment?
Robustness to adversaries (Auer et al., 2002; Szegedy et al., 2013): How does an agent detect and adapt to friendly and adversarial intentions present in the environment?
Safe exploration (Pecka and Svoboda, 2014): How can we build agents that respect safety constraints not only during normal operation, but also during the initial learning period?
For precise information, one can refer to the original paper linked at the end.
So if we are looking for a regular everyday normal AI product, it could be a resemblance of the following.
Ending note :
In conclusion, the field of AI safety presents both exciting opportunities and significant challenges. As we delve deeper into the realm of artificial intelligence during our studies, it becomes increasingly important to acknowledge the vast potential it holds for positively reshaping our world. AI has the capacity to boost efficiency and tackle problems, potentially revolutionizing various industries and aspects of our daily lives.
However, creating a course towards a secure and ethical AI future comes with its set of obstacles. Issues like bias, transparency, accountability, and unintended consequences emphasize the pressing need for a robust framework that prioritizes ethical considerations. Achieving the delicate equilibrium between fostering innovation and ensuring responsible development becomes crucial in guaranteeing that AI contributes positively to humanity.
Continuous debates and discussions go such as :
Therefore my research will continue and I hope to study further in the field.
Thank You for reading !
Links for references :
Concrete Problems in AI Safety
Faulty reward functions in the wild
Also recent hot topic I have been researching about in this field could include :