



How LLMs are compared?
There are a few main ways researchers benchmark the performance of huge language models (LLMs) in natural language processing. A common tactic is testing the models on standard datasets used by lots of NLP folks. These datasets have examples and questions for specific tasks like answering questions, inferring meaning from text, analyzing sentiment, and more. Checking the model's accuracy at these tasks compared to other models shows how well it does.
Public leaderboards also let everyone see how new LLMs stack up against each other. The models are ranked based on their overall scores across the different tasks.
On top of performance metrics, human reviews are critical for judging LLMs too. People rate the text generated by the models on qualities like fluency, coherence, and factual correctness. This gives insights into how natural and appropriate the language generation abilities are.
Researchers also do ablation studies*, removing or tweaking components of an LLM to understand their impact on benchmark performance. This highlights which architecture innovations are most important. Compute efficiency is another big evaluation dimension, since training LLMs requires massive resources. More efficient models are preferred.
In a nutshell, benchmarking uses quantitative metrics on standard tests, human quality ratings, error analysis by tweaking models, and compute efficiency comparisons. This multi-angle approach aims to robustly evaluate LLMs against the state-of-the-art. But what exactly is state-of-the-art?
Note : What is an ablation study?
In artificial intelligence and machine learning, ablation means removing or disabling a component of an AI system in order to study and understand it better. Researchers conduct ablation studies by cutting out or turning off parts of an AI system and then analyzing the impact on performance.
'LMSYS Chatbot Arena is a crowdsourced open platform for LLM evals'
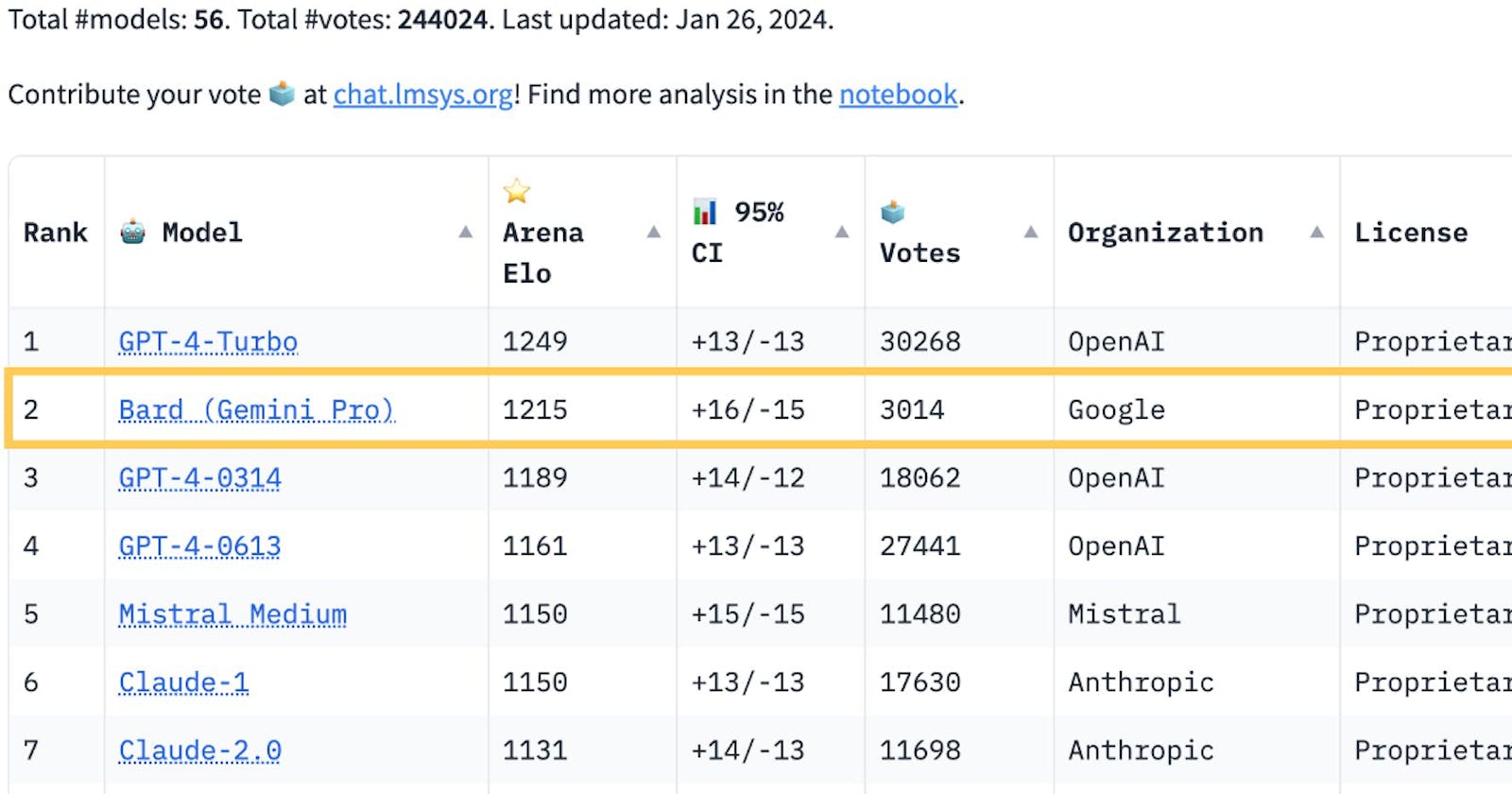
A recent change in the Arena leaderboard has sparked an interest in how people rank and evaluate the different language models. Arena is mostly user voted so end experience for the user should be kept in mind in my opinion.
So Google finally made a comeback after weeks of slander both on social media as well as other more 'intellectual' forums. But as it turns out nothing lasts forever and for Google there were questions.
This calls for correct/fixed evals for specific models. And the transparency behind the submissions for these models. People need to be educated about comparisons of various tools. Like in the following tweet we see :
The 'Judgement' of LLMs
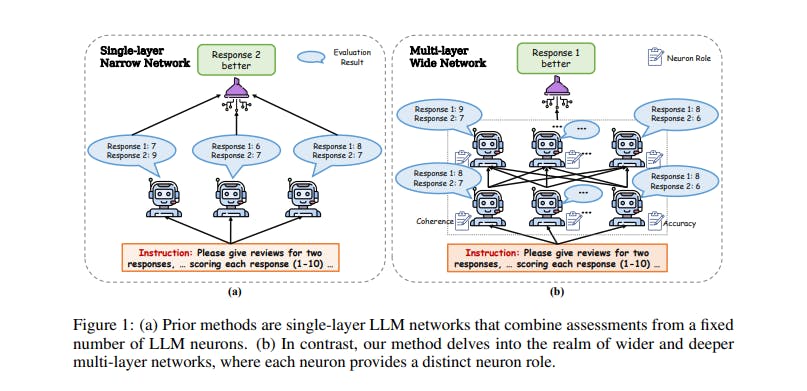
In many research papers such as "Wider and Deeper LLM Networks are Fairer LLM Evaluator" & "Evaluating Large Language Models: A Comprehensive Survey", we see the ways and experiments on comparing various models to their effort. Without specifying the domain for evaluation, one cannot be sure about the indifferences of any of the models in said question. In the recent emergence of large models, the NLP community had organized shared tasks like SemEval, CoNLL, GLUE, SuperGLUE, and XNLI to evaluate these models. These tasks gather scores for each model, giving a comprehensive measure of its overall performance.
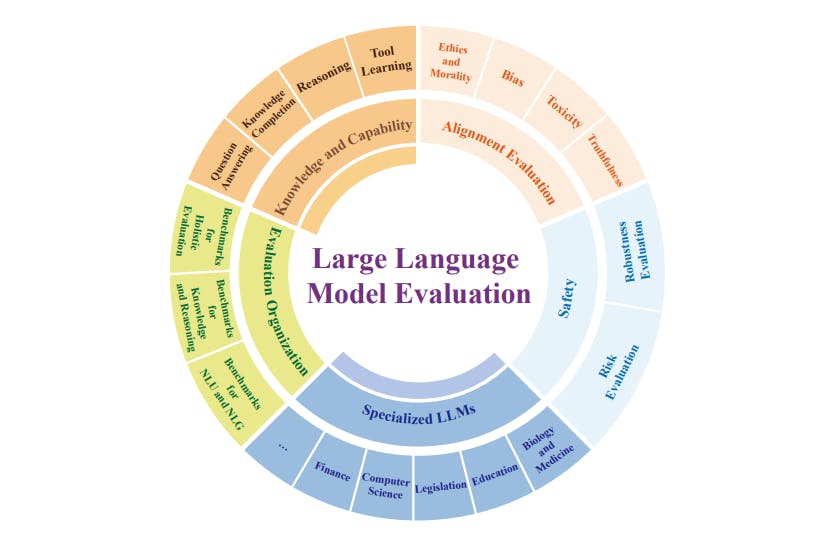
So, a comprehensive and versatile LLM should be well functioning in MOST of the benchmark specifications provided the mode of evaluation is same for all. A universal standard or a pipe dream which might very well be made as the blog is being written.
Conclusion :
So, we get that LLM comparison should be based on equal evals and on fixed experimental setups or QAs. Active conversions about the comparisions between models should be encouraged. The exact studies go on and we can see the internet community partaking actively as usual. Further updates should be expected in future posts. Thank you for reading.
but sometimes it falls.......
Links/References
Wider and Deeper LLM Networks are Fairer LLM Evaluators
Evaluating Large Language Models
Updates :
Following the hype, some recent updates on the topic can be found below as a series of original tweets which are sufficient for a quick read themselves.